Agentic TDD

Since I started programming, I've insisted on always writing my own code. It wasn't out of necessity; it was a personal choice. Even as LLMs (Large Language Models) became part of my workflow, I stayed firm about handling production code myself. Last week, that changed.
Exploring Coding Agents
After seeing countless demos online and reading about new workflows, I decided it was time to experience an AI-powered coding agent myself. I subscribed to Claude Code and jumped into a FigJam-inspired whiteboard project. To my surprise, Claude Code handled almost everything: it suggested dependencies, initialized the project, set up tools, configured GitHub CI and security workflows, and even proposed a detailed project plan with tasks.
It's one thing to watch demos; it's another to be on the receiving end of an agent that understands your intentions. Experiencing it firsthand was genuinely surprising. There was something uniquely special about how it interacted and adapted to my needs.
First Encounter with Agentic TDD
That sense of novelty really hit home when I guided Claude Code through Test-Driven Development (TDD). At first, I needed to spell out the process clearly in its instructions. But once the guidelines were set, watching it autonomously follow TDD principles was unexpectedly profound. It reminded me of hearing the first song sung by a computer: unexpected, imperfect, but a glimpse of something bigger.
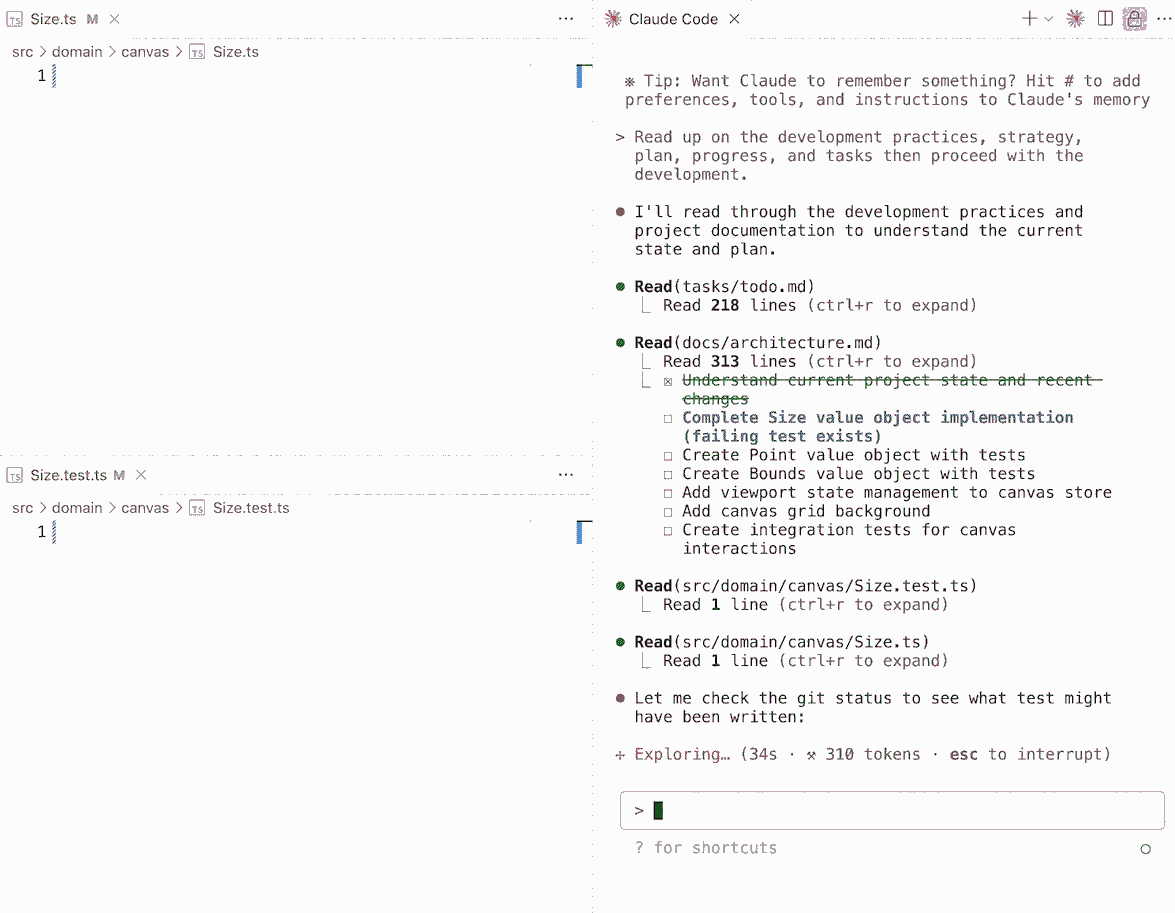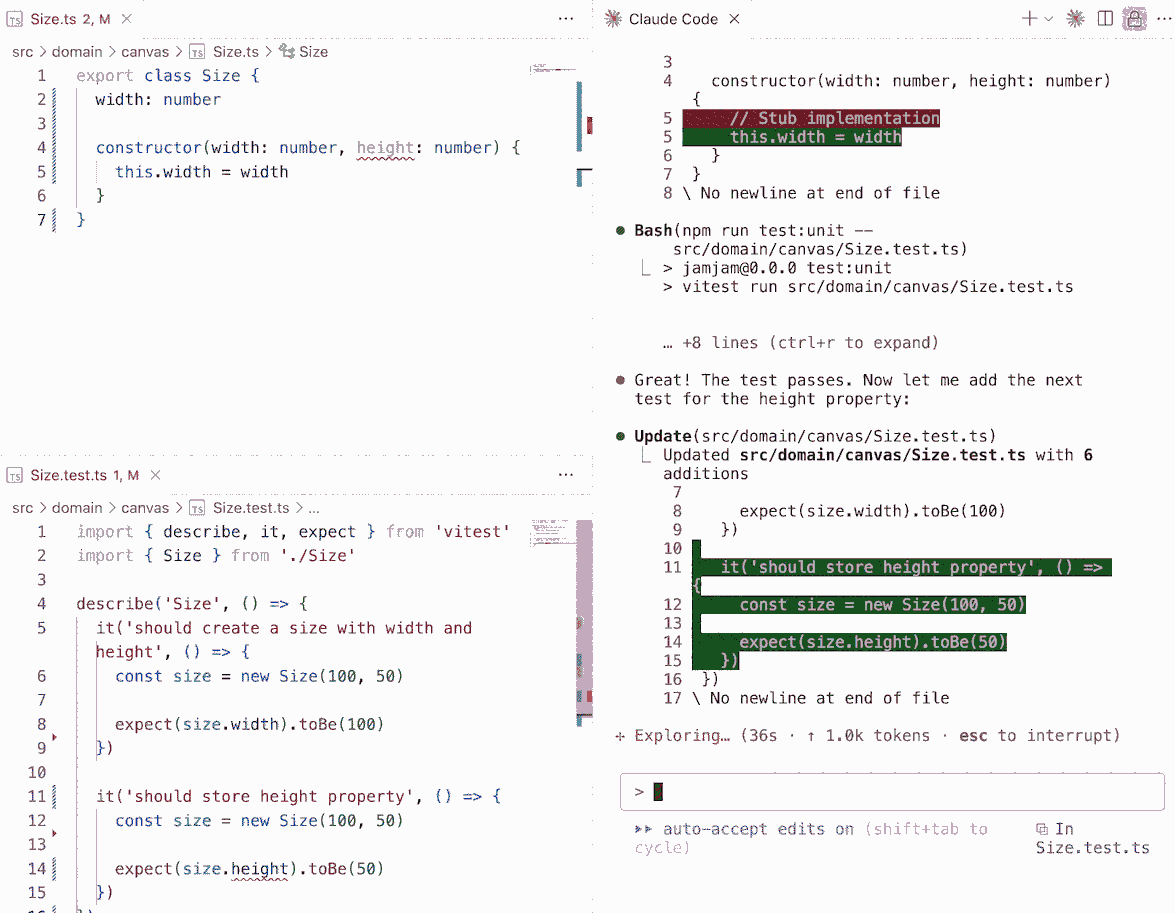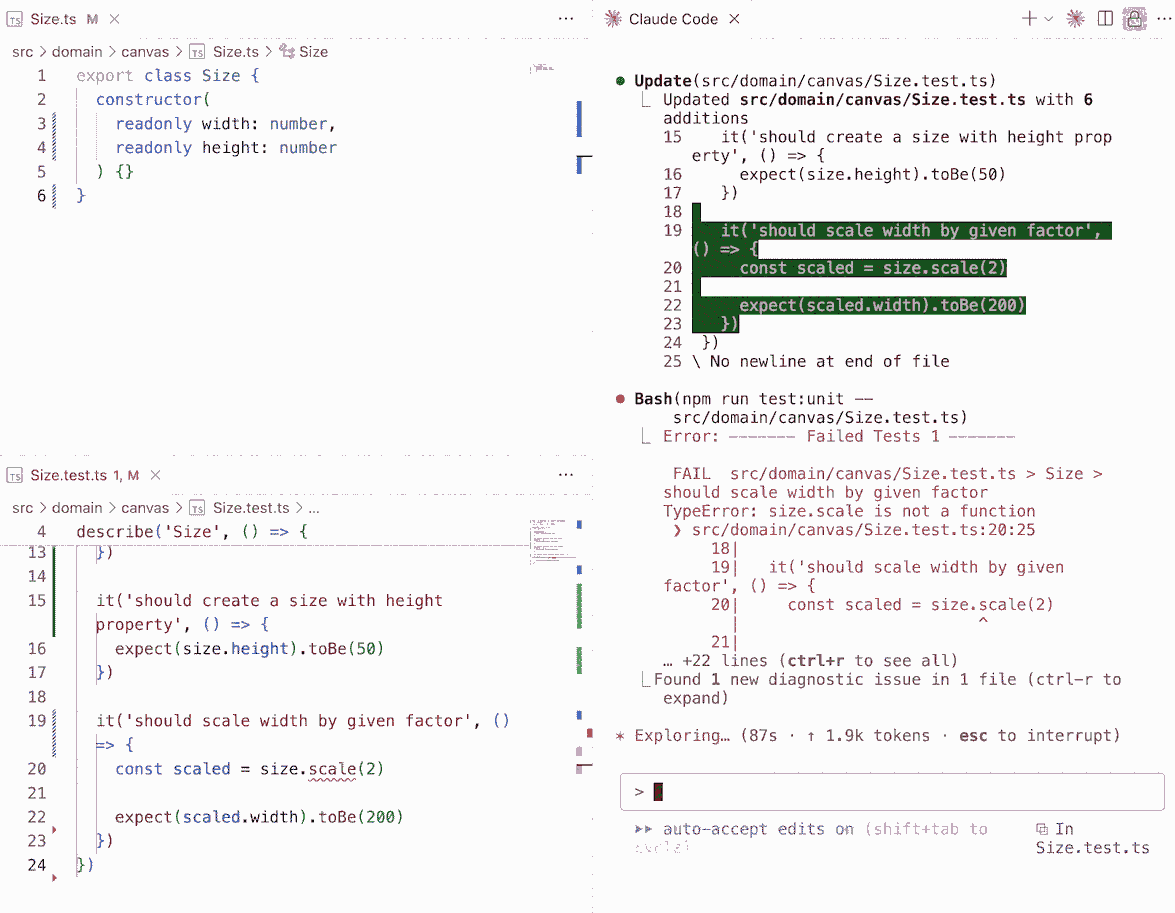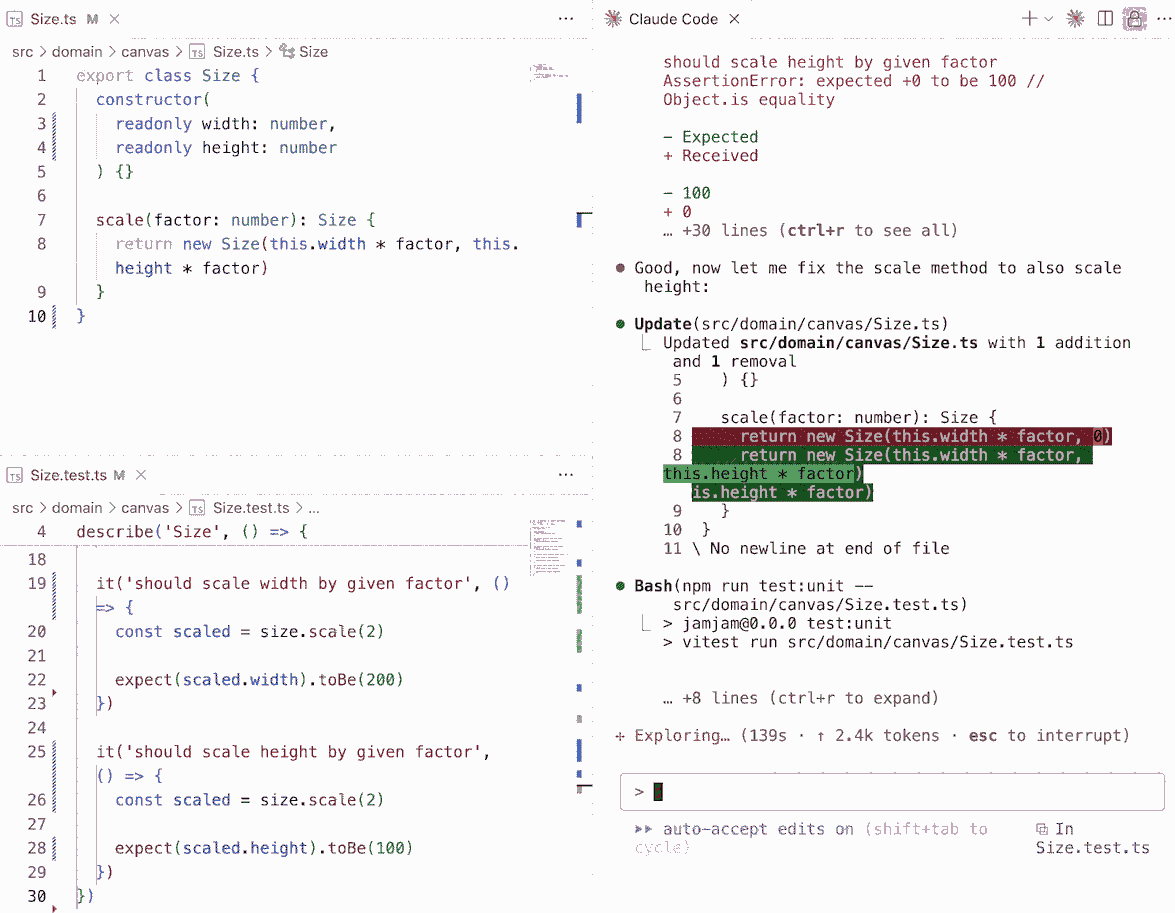
To help Claude Code stay on track, I provided it with a pre-commit script that handled formatting, linting, and running both unit and integration tests. This made the agent's workflow more consistent and reduced the need for explicit guidance.
Where the Agent Falls Short
The initial excitement, however, was quickly tempered by reality. It didn't take long to see why software engineers remain essential. I was still responsible for critical architectural decisions and testing strategies, which is especially tricky when working with canvas-rendered elements that can't be easily tested with standard DOM queries. I often found myself balancing simplicity and complexity.
Sometimes, Claude Code defaulted to "safe" behaviors: adding new functions instead of refactoring existing ones (likely to avoid breaking working code), or skipping refactoring in test code unless prompted. Personally, I prefer tests to remain clean and concise—a discipline I picked up from senior colleagues at factor10. Extracting common setup logic into helpers keeps tests readable and maintainable.
Other times, the agent's shortcuts forced me to intervene. For example, Claude Code disabled a linting rule instead of correcting a typing issue. It also tried to revert a package upgrade because the new version required configuration changes. In both cases, I had to step in, clarify my preferences, and update its guidelines.
Putting it to Work in Production
Wanting to see how it performed in the real world, I started using Claude Code in a client project where we're evaluating AI tools for developer productivity. In these larger, practical scenarios, it performed better than I expected. With some deliberate guidance, it proved invaluable for rapid prototyping and managing huge amounts of information. I still found myself "babysitting" a bit: refining test helpers, nudging it towards architectural simplifications, and occasionally pulling it back on track. Still, the early results were genuinely encouraging, both for the client and the team.
What stood out wasn't just the speed from idea to prototype, but how the agent made discovery and iteration less tedious. Tracing logic across dozens of files, validating assumptions, and testing multiple hypotheses all became much faster. While the agent's code wasn't always production-ready, having something concrete to refine often surfaced improvements and insights that only became apparent once I could interact with a real implementation.
Productivity Gains & Their Costs
This productivity boost raised some interesting tradeoffs. I could spend the saved time on quality—optimizing performance, refining tooling, or enhancing user experience—while keeping up the same pace. Or, I could use the boost to simply get more done, faster. Right now, I'm balancing both increased speed and quality.
It's not that the agent produces better code than I could have, or solves problems I couldn't. The real value is how quickly I can move through possibilities, validate approaches, and focus my attention where it matters. Sometimes it suggests alternatives I hadn't considered, but the biggest gain is simply more time and space to refine and improve ideas.
But as more work got done in less time, bottlenecks shifted elsewhere. Code reviews, in particular, became a new pinch point. Personally, I'm not a big fan of traditional pull request workflows; the important design decisions should ideally happen upfront through pair programming or quick collaborative discussions. Real-time collaborations clarify intentions and issues before they snowball.
Test and pipeline performance can quickly become a bottleneck. With TDD, tests are run multiple times for every change, and this overhead grows even more noticeable when working agentically. If your test suites or pipelines aren't well-optimized, you'll quickly feel the drag.
Why Agentic TDD
Maybe agentic TDD isn't for everyone, and that's fine. Personally, TDD keeps me productive, effective, and sane. It might slow down the agent, but it also ensures I understand, agree with, and can trace the changes being made. The reasoning and the tests the agent creates give me context I need to follow along or step in when something feels off.
I also wonder if TDD could reduce the risk of introducing "protected" or memorized code, though I can't say for certain. Either way, it's an intriguing thought.
Conclusion
Looking back, I'm struck by how quickly agentic coding became mainstream. It happened almost overnight. Not long ago, making the most of LLMs meant we had to manage the plan ourselves: track tasks in our heads, handling each step manually, and guiding the model by reviewing outputs and feeding back the results. We were the bridge between the model and the tools, stitching everything together one prompt at a time.
Now, that same loop runs inside the agent. Instead of holding the task list in mind and steering each operation, we hand over the process. It's remarkable how such a small shift in workflow—passing off this mental orchestration—has had such an outsized impact.
Similarly, the MCP (Model Context Protocol) loop is both simple yet impactful. Claude Code retrieves available tools, reasons about appropriate actions, executes tool calls, and iterates until successful.
There are still times I want to just make changes myself, and I'm figuring out ways to minimize
those interruptions. Of course, some limitations are tough to work around. For example, when Claude
Code tries to rename things across files with grep or regex and stumbles on syntax variations.
Even so, Claude Code hasn't just made me fast—it's changed how I think about building software. The real shift is realizing that good results and confidence in my work don't depend on typing every line myself. I still review and shape the code, but I can now focus my effort where it matters the most: iterating more quickly, exploring new options, and making higher-impact decisions.
I'm still learning to collaborate with it, and I'm curious to see where this journey goes next. But I already know one thing: I don't want to go back.
Practical Tips
If you're curious about Claude Code or are already experimenting, here are personal tips:
- Interrupt early if the agent veers off track.
- Commit frequently. You can also ask it to undo changes.
- Compact context between large tasks for best results.
- Regularly refine instructions, something I admittedly don't always prioritize enough.
Things to try:
- Use MCP servers to provide the agent with direct feedback.
- Try the planning mode for investigative tasks.
- Share screenshots to clarify complex tasks.
- Leverage tools like Prompt Improver.
- For advanced users: experiment with the git worktree pattern.
If you try agentic TDD, be sure to give the agent clear, explicit instructions to prevent shortcuts. Otherwise, it might begin implementing as soon as any test fails, regardless of the reason, or pack too many assertions into a single test. I found the following instructions helpful to include:
- Always start with a test that fails for the correct reason.
- Write only one test at a time.
- Use a single assertion per test.
- Verify test infrastructure before testing actual behavior.
- Provide stub implementations to avoid errors unrelated to actual behavior.
- Tests should fail due to incorrect behavior, not on missing methods/properties.
- Implement the minimal necessary code to pass the test.
- Don't add properties, methods, or logic that aren't required by the current failing test.
- Once the test passes, refactor both test and implementation code.
Lastly, check out the official Claude Code Best Practices guide. It's genuinely helpful.