Robot Control with the Jetson Nano

Side view of the assembled robot built for this project
Two years ago, I got to dive into a project at the intersection of machine learning and hardware - right before ChatGPT became a household name and when terms like overfitting puzzled me. Nonetheless, I was really excited about it, especially because it involved both software and hardware, a combination I'm quite fond of.
The project was part of the Nvidia Jetson AI Certification program, which challenges participants to demonstrate their machine learning skills using the Jetson Nano Developer kit. Essentially, the kit is an embedded computer designed specifically to accelerate machine learning applications. Though not required, I also had access to a robot, which I was eager to use.
I set a goal to train a model that would enable the robot's arm to be controlled via hand gestures. The robot was equipped with a small camera on its front, perfectly positioned for this task.
Image Classification
I began with image classification, where the model is trained to identify and categorize images into specific classes. My goal was to recognize four hand gestures:
- Thumbs up
- Thumbs down
- Fingers spread
- Fingers together
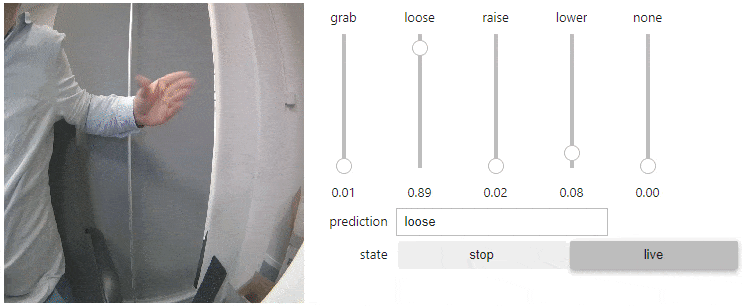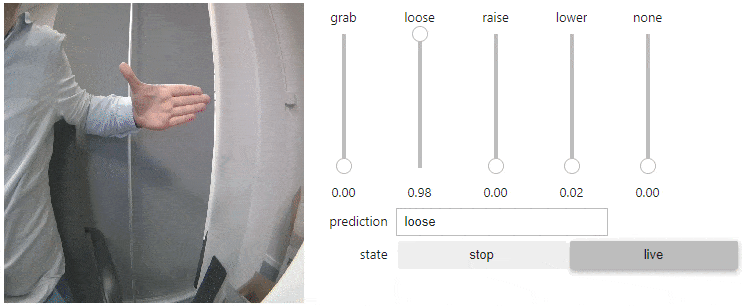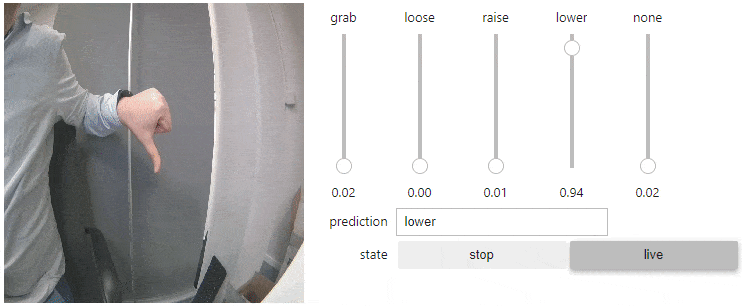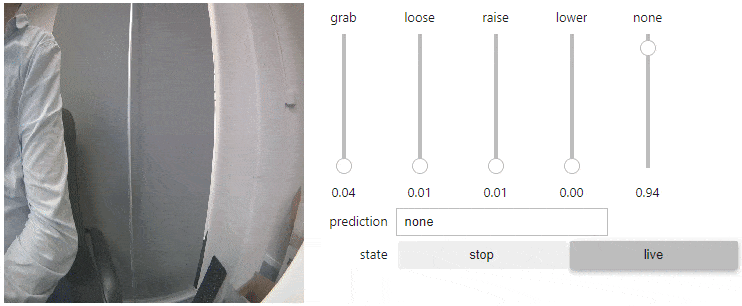
This allowed me to command the robot's arm and grip movement using these gestures. However, it was somewhat hit-or-miss. The approach was basic, capable of only recognizing one gesture at a time, which limited the ability to control the arm's elevation and grip simultaneously.
Moreover, the control was binary; It lacked the nuance to specify degrees of movement or grip tightness, posing a challenge for precise control.

Image Regression
Moving forward, I explored image regression. Unlike classification, this method involved training the model to pinpoint my hand's features in images, providing coordinates for my fingertips. The challenge then became translating these coordinates into accurate robot movements.

A significant hurdle was accounting for the camera's depth perception, essential for distinguishing between fingertips being spread apart versus the hand moving closer to the camera.
I experimented with measuring distances between various hand landmarks as proxies for depth perception, such as the distance from the thumb's top and the wrist's bottom corner, or between the tips of the index and pinky fingers. This approach, however, introduced additional complexity and new challenges, such as adjusting for the hand tilting and panning.
Ultimately, the model's error margins and the camera's limitations led me to simplify my approach. I chose to track only the thumb and index finger while maintaining a constant distance from the camera. This simpler model achieved more predictable results and easier control.

While the project may seem straightforward, it was incredibly insightful, making the seemingly complex field of machine learning feel much more attainable.
Every so often, I reflect on this project and wonder if a simpler solution exists for accurately considering distance. An intriguing possibility that comes to mind is the use of two cameras, mirroring the binocular vision of humans, to facilitate a more straightforward approach to depth perception. This idea excites me, and I'm keen to explore it further, possibly revisiting the project with a new perspective in the future.
You can find the source code and assembly instruction on my GitHub repo. If you are curious about machine learning or robotics, I encourage you to give it a look - who knows what you might discover?